
When it comes to business conversations about Uber, they tend to veer in one of two directions: the ride hailing platform’s pending* Initial Public Offering (IPO), or its ability to enrage taxi drivers and regulators around the world (the German Taxi and Rental Car Association is the latest to urge a strike) by radically disrupting entrenched markets.
Typically less discussed is the San Francisco-headquartered company’s ability to steadily produce an eclectic – and typically polished and useful – array of open source tools for developers. (We touched on Uber’s free geospatial application Kepler last June; which is in turn built on deck.gl; Uber’s web.gl data visualisation tool.)
It’s latest may be the most compelling yet.
Introducing Ludwig
Ludwig, a new TensorFlow-based toolkit that enables users to train and test deep learning models without writing any code, drew comparatively little attention outside the engineering world when Uber open sourced it in February.
![]()
The inattention was undeserved: it’s an intriguing tool that allows deep learning dilettantes to quickly train and test deep learning models without having to write code, while making it much easier for experts to test new ideas and perform standard data preprocessing and visualisation.
What it Does…
Ludwig lets users train a deep learning model by providing a tabular file (like CSV) containing the data and a YAML configuration file that specifies which columns of the tabular file are input features (individual properties being observed) and which are output target variables.
The simplicity of the configuration file enables faster prototyping, potentially reducing hours of coding down to a few minutes. If more than one output target variable is specified, Ludwig will perform multi-task learning, learning to predict all the outputs simultaneously, a task that usually requires custom code, Uber notes.
(Ludwig also provides a simple Python programmatic API that lets users train or load a model and use it to obtain predictions on new data).
As Uber’s Piero Molino, Yaroslav Dudin, and Sai Sumanth Miryala noted in a blog announcing the launch: “We originally designed Ludwig as a generic tool for simplifying the model development and comparison process when dealing with new applied machine learning problems.”
“In order to do so, we drew inspiration from other machine learning software: from Weka and MLlib, the idea of working directly with raw data and providing a certain number of pre-built models; from Caffe, the declarative nature of the definition file; and from scikit-learn, its simple programmatic API. ”
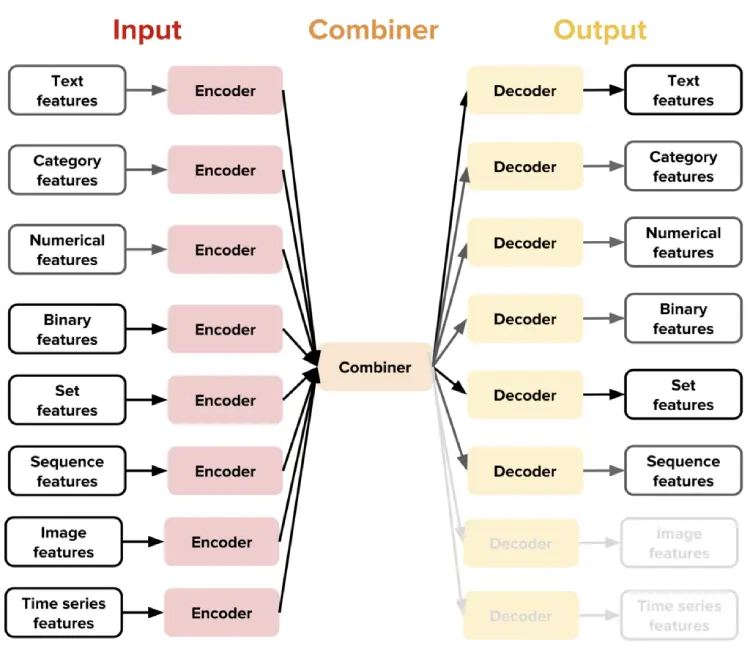
“This mix of influences makes it a pretty different tool from the usual deep learning libraries that provide tensor algebra primitives and few other utilities to code models, while at the same time making it more general than other specialized libraries like PyText, StanfordNLP, AllenNLP, and OpenCV.”
While there is no shortage of deep learning toolkits in the market, Ludwig’s a bold effort that has been widely deployed in-house at Uber to streamline and simplify the use of deep learning models in applied projects, “as they usually require comparisons among different architectures and fast iteration.”
The company has used it for information extraction from driver licenses, “identification of points of interest during conversations between driver-partners and riders” (yes, that one deserves closer scrutiny) food delivery time prediction, and much more.
Ludwig’s developer guide is here.
*Uber’s prospectus dropped on Thursday. It reveals that Uber had $3 billion in operating losses in 2018 and $10.1 billion over the last three.




