
MapR is moving to more embrace cloud technology with the release of a cloud-scale data store to manage files and containers.
The MapR-XD fits into the company’s Converged Data Platform and is said to support any type of data type from the edge to the data centre and multiple cloud environments with automatic policy-driven tiering from hot, warm, or cold data.
The company said that the new product gives customers the ability to create vast, global data fabrics which are ready for analytical and operational applications, essentially making it easier to use data.
“As applications become more intelligent and take advantage of more diverse data in real time, for both analytical and operational uses, there arises the need for new approaches to data processing,” said Matt Aslett, research director, data platforms and analytics, 451 Research. “MapR-XD is designed to eliminate data silos and support new use cases as they emerge that require data processing from the edge, data centre and to the cloud.”
Read more: MapR claims open source big data victory with patent award
Included in the MapR-XD is files and container support with the product said to eliminate data silos and simplify management across files and containers. It is also said to be able to scale to support trillions of files and exabytes of data.
MapR-XD also aims to make the most of the power of network interconnects and is said to take advantage of the underlying heterogeneous hardware. On this front it offers automated capabilities such as logical partitioning, parallel processing for disparate workloads, and bottleneck avoidance with I/O shaping and opimisations.
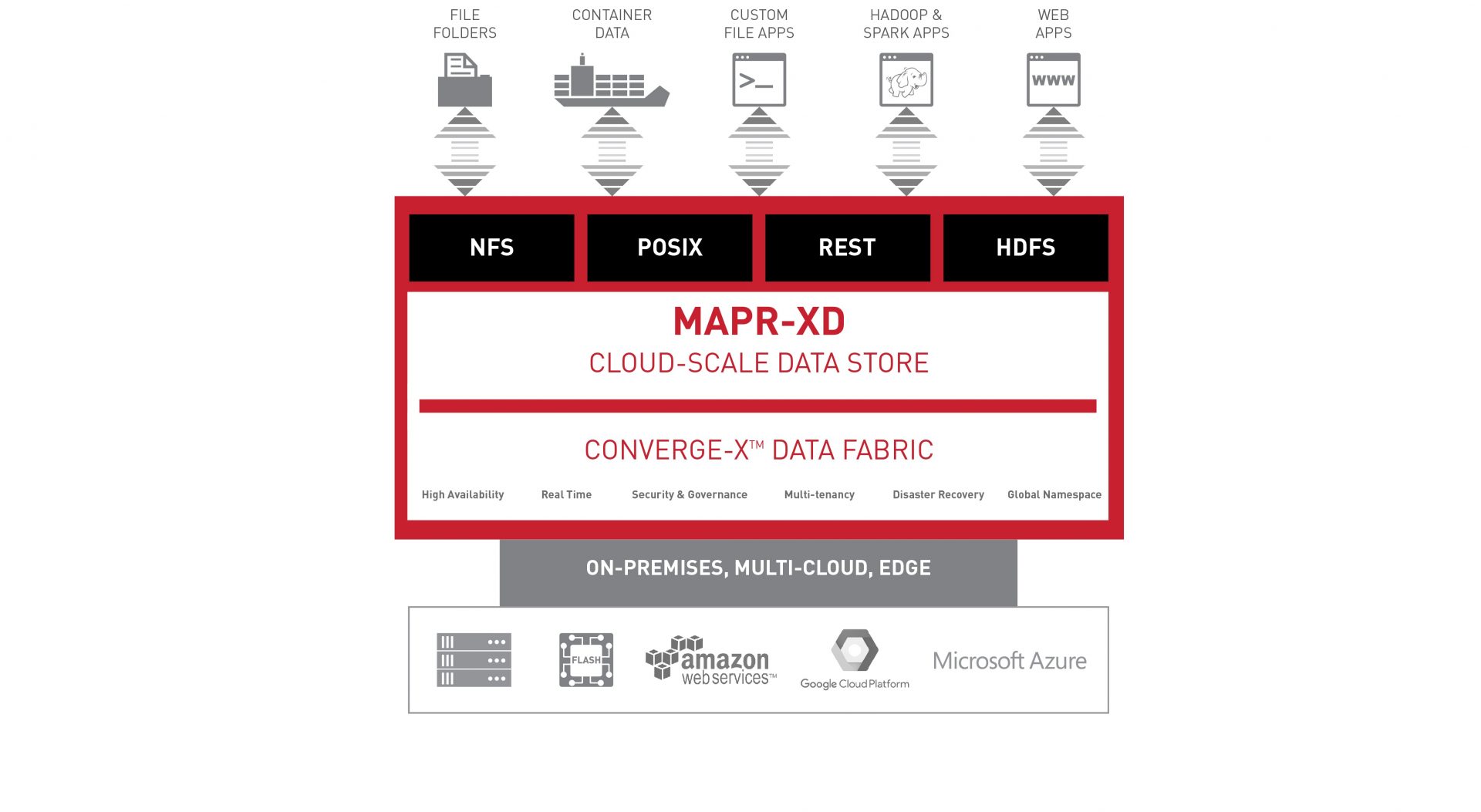
The product also includes an optimised container client that support both legacy and new containerised event-based microservices applications, containers, database and event streams, and works with multiple schedulers such as Kubernetes, Mesos, and Docker Swarm.
On the cloud front the product supports edge, on-premises, and cloud environments and allows for multi-temperature capabilities across flash, disk, and cloud tiers.




