
Google Cloud Platform (GCP) says it has radically revamped BigQuery, the enterprise data warehouse managed service that is arguably the flagship product in GCP’s stack.
The move is intended to remove data streaming bottlenecks and boost performance/capacity significantly for streaming workloads like those from the IoT.
A rebuild of its back-end means it’s now 10-times faster, with the default Streaming API quota lifted from 100,000 to 1,000,000 rows per second per project. Maximum bytes per second are also up from 100MB per table to 1GB per project.
There are also now no table-level limitations.
(BigQuery has a SQL interface, can be accessed via the GCP Console, a web UI, using a command-line tool, or by making calls to the BigQuery REST API using client libraries such as Java, .NET, or Python. It is commonly used to ingest and analyse data; another recent upgrade lets users run TensorFlow machine learning models in it…)
There have been no changes to the streaming API as a result of the new back-end.
BigQuery Capacity Boost
GCP has also expanded support for federated queries, or external data sources that you can query directly through BigQuery, to include its own Cloud SQL.
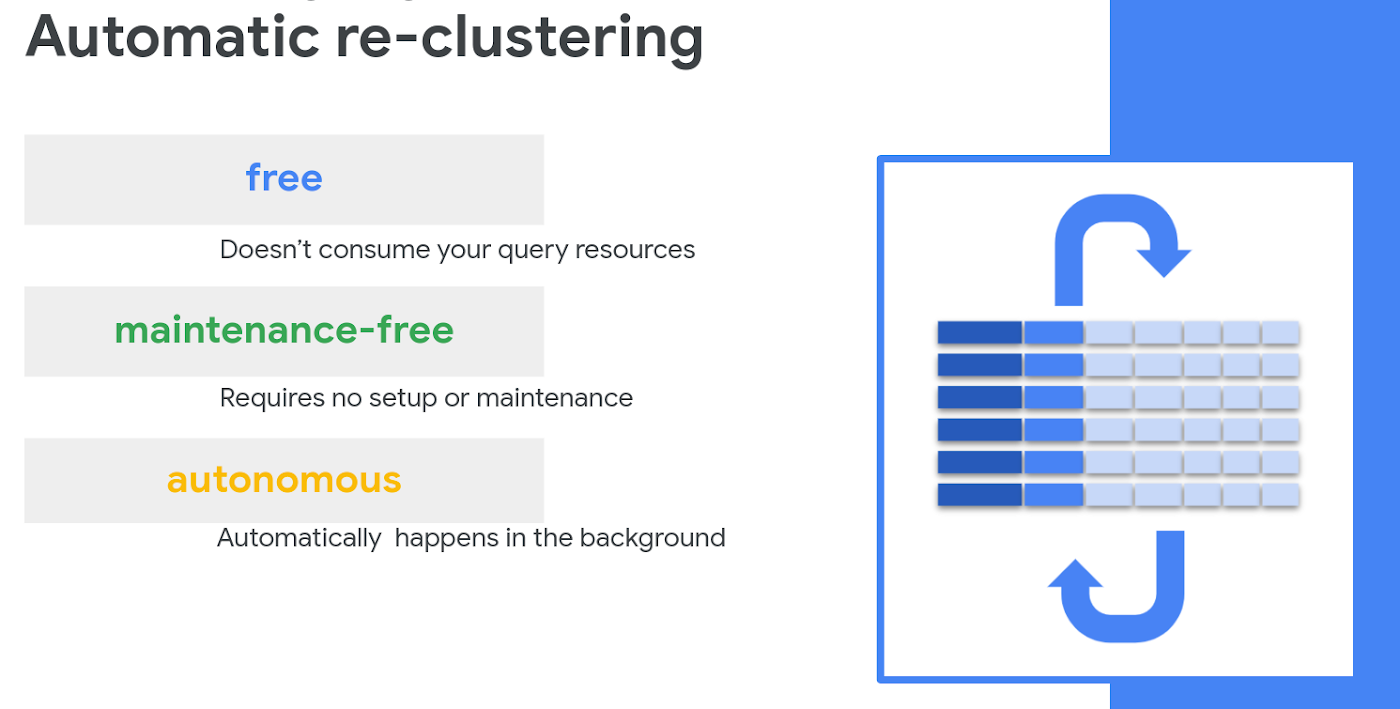
The company’s Evan Jones said in a blog that other upgrades include “automatic re-clustering”.
He explained: “Efficiency is essential when you’re crunching through huge datasets. One key best practice for cost and performance optimization in BigQuery is table partitioning and clustering.
“As new data is added to your partitioned tables, it may get written into an active partition and need to be periodically re-clustered for better performance. Traditionally, other data warehouse processes like “VACUUM” and “automatic clustering” require setup and financing by the user. BigQuery now automatically re-clusters your data for you at no additional cost and with no action needed on your part.”
(When customers create and use clustered tables in BigQuery, their charges are based on how much data is stored in the tables and on the queries they run against the data).
See also: Google Eases Access to Public Data Sets




